MPEG-4 covers the the whole range of digital audio:
Structured Audio Tools
MPEG-4 comprises of 6 Structured Audio tools are:
Very briefly each of the above tools have a specific function
SAOL (Structured Audio Orchestra Language)
SAOL is pronounced like the English word "sail" and is the central part of the Structured Audio toolset. It is a new software-synthesis language; it was specifically designed it for use in MPEG-4. You can think of SAOL as a language for describing synthesizers; a program, or instrument, in SAOL corresponds to the circuits on the inside of a particular hardware synthesizer.
SAOL is not based on any particular method of synthesis. It is general and flexible enough that any known method of synthesis can be described in SAOL. Examples of FM synthesis, physical-modeling synthesis, sampling synthesis, granular synthesis, subtractive synthesis, FOF synthesis, and hybrids of all of these in SAOL.
There's a page on using MIDI to control SAOL available at
http://sound.media.mit.edu/mpeg4-old/
SASL (Structured Audio Score Language)
SASL is a very simple language that was created for MPEG-4 to control the synthesizers specified by SAOL instruments. A SASL program, or score, contains instructions that tell SAOL what notes to play, how loud to play them, what tempo to play them at, how long they last, and how to control them (vary them while they're playing).
SASL is like MIDI in some ways, but doesn't suffer from MIDI's restrictions on temporal resolution or bandwidth. It also has a more sophisticated controller structure than MIDI; since in SAOL, you can write controllers to do anything, you need to be able to flexibly control them in SASL.
SASL is simpler (or more "lightweight") than many other score protocols. It doesn't have any facilities for looping, sections, repeats, expression evaluation, or some other things. Most SASL scores will be created by automatic tools, and so it's easy to make those tools map from the intent of the composer ("repeat this block") to the particular arrangement of events that implement the intent.
SASBF (Structured Audio Sample Bank Format)
SASBF (pronounces "sazz-biff"!!!) is a format for efficiently transmitting banks of sound samples to be used in wavetable, or sampling, synthesis. The format is being re-examined right now in hopes of making it at least partly compatible with the MIDI Downloaded Sounds (DLS) format.
The most active participants in this activity are E-Mu Systems and the MIDI Manufacturers Association (MMA).
MIDI Semantics
As well as controlling synthesis with SASL scripts, it can be controlled with MIDI files and scores in MPEG-4. MIDI is today's most commonly used representation for music score data, and many sophisticated authoring tools (such as sequencers) work with MIDI.
The MIDI syntax is external to the MPEG-4 Structured Audio standard; only references to the MIDI Manufacturers Association's definition in the standard. But in order to make the MIDI controls work right in the MPEG context, some semantics (what the instructions "mean") have been redefined in MPEG-4. The new semantics are carefully defined as part of the MPEG-4 specification.
Scheduler
The scheduler is the "guts" of the Structured Audio definition. It's a set of carefully defined and somewhat complicated instructions that specify how SAOL is used to create sound when it is driven by MIDI or SASL. It's in the style of "when this instruction arrives, you have to remember this, then execute this program, then do this other thing".
This component of Structured Audio is crucial but very dull unless you're a developer who wants to implement a SAOL system.
AudioBIFS
BIFS is the MPEG-4 Binary Format for Scene Description. It's the component of MPEG-4 Systems which is used to describe how the different "objects" in a structured media scene fit together. To explain this a little more: in MPEG-4, the video clips, sounds, animations, and other pieces each have special formats to describe them. But to have something to show, we need to put the pieces together - the background goes in the back, this video clip attaches to the side of this "virtual TV" object, the sound should sound like it's coming from the speaker over there. BIFS lets you describe how to put the pieces together.
AudioBIFS is a major piece of MPEG-4 that has designed for specifying the mixing and post-production of audio scenes as they're played back. Using AudioBIFS, we can specify how the voice-track is mixed with the background music, and that it fades out after 10 seconds and this other music comes in and has a nice reverb on it.
BIFS is generally based on the Virtual Reality Modeling Language (VRML) (See Later in Course), but has extended capabilities for streaming and mixing audio and video data into a virtual-reality scene. The AudioBIFS functions are very advanced compared to VRML's sound model, which is rather simple, and are being tentatively considered for use in a future version of VRML.
In MPEG-4, AudioBIFS allows you to describe a sound as the combination of a number of sound objects. These sound objects may be coded using different coders (for example, CELP-coded voice and synthetic background music), and combined together in many ways. We can mix sounds together, or apply special filters and other processing functions written in SAOL.
Like the rest of BIFS, AudioBIFS is based on a scene graph. However, unlike in visual BIFS, the nodes in the AudioBIFS scene graph don't represent a bunch of objects which are presented to the user. Each AudioBIFS sound subgraph represents one sound object which is created by mixing and processing the elementary sound streams on which it is based.
For example, Fig 6.10 audio subgraph which shows how a simple sound is created from three elementary sound streams:
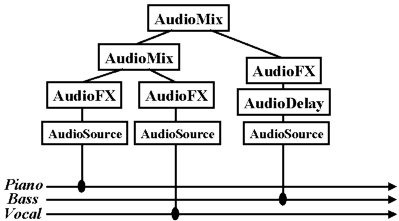
AudioBIFS Subgraph
Each of the rectangles show a node in the audio scene subgraph. Each node has a certain function, like mixing some sounds together, or delaying a sound, or doing some effects-processing. The arrows along the bottom represent the three elementary sound streams which make up the sound object. Each sound stream can be coded a different way. For example, we might code the piano sound with the Structured Audio decoder, the bass sound with the MPEG-4 Parametric HILN coder, and the vocal track with the MPEG-4 CELP coder.These three sound streams are just like a "multitrack" recording of the final music sound object. The sound of each instrument is represented separately, then the scene graph mixes them all together. The processing in the audio subgraph is like a "data-flow" diagram. The sounds flow from the streams at the bottom, up through the nodes, and turn into a single sound at the top.
This single, final sound can be put into an audiovisual scene: it can be given a 3-D spatial location, moved around, and so on.
There's a page on AudioBIFS available at
http://www.risc.rockwell.com/349/343/MPEG4/