


Next: About this document
Up: No Title
Previous: Scheduling - A Nightmare!!!
Natural Completion
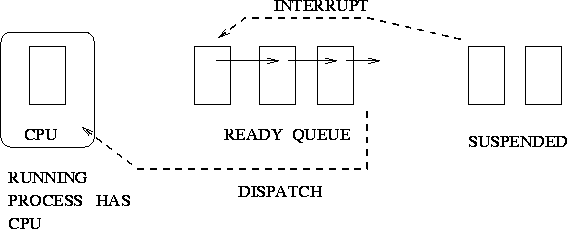
Figure 4:
- Process runs until it either completes or suspends itself by :
making a kernel call, cause an error trap or completes and leaves system (unix
zombies)
- The runnable process is placed at the end of the ready queue.
Preemption
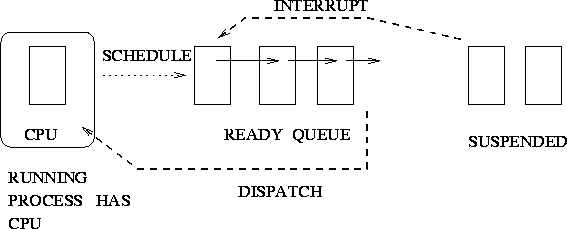
Figure:
- Interrupt causes suspended process to become runnable depending on priority
- Insert in ready queue in priority order (i.e. at head of queue)
- Dispatcher picks the new high priority process first
Simpler ?
- FIFO : First in first out (usually meant one program kept CPU until it
completely finished - uniprogramming) - aka FCFS (first come first serve)
+ simple
- short jobs get stuck behind long ones
- Solution ? - Add a timer, and preempt CPU from long-running processes (or jobs).
Just about every real OS does something of this flavour.
Time Slice with Quantum size
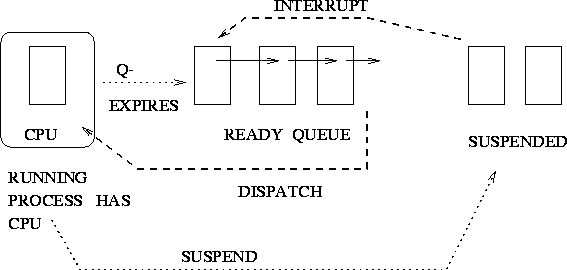
Figure:
- Process runs until time slice (quantum) expires
- aka round robin scheduling
- What should be the size of the quantum ? (too large
 FIFO,
too small too many context switches)
FIFO,
too small too many context switches)
- Optimal is a design parameter
- Effective in time sharing environments (reasonable response time
for interactive users)
- selfish round robin : processes wait in a holding queue
until their priorities reach active queue priorities
Typical time slices : 10-100 millisecs; typical o/head : 0.1 - 1 millisec
Overhead = 1%
STCF and SRTCF
- STCF : Shortest time to completion first
- SRTCF : Shortest remaining time to completion first. Preemptive version
of STCF, if job with shorter time to completion arrives, give CPU to new job
- Idea : get short jobs out of system (cf answering exam questions?) - Big effort
on short jobs, small effect on big ones. Improved average performance
The crystal ball
- STCF/SRTCF : require knowledge of future
- How do you know how long program will run for ?
- Ask user ? What if job takes more ? Kill job ? - Bankers algorithm
- Predicting response of system based on past : very common occurance
in computing
- Program behaviour is regular, most of the time - Exploit this ! (Locality)
Multilevel feedback
- adaptive : change scheduling policy (method) based on past behaviour
- Multiple queues, each with different priority
- OS does round robin at each priority level - run highest priority job first -
on completion the next priority job etc
- Round robin time slice increases exponentially at lower priorities
- Priority adjustment is as follows :
Job starts in highest priority queue
If timeout expires, drop one level
If timeout does not expire, push up one level (or back to top)
- Result approximates SRTCF : CPU bound processes drop like a rock, others
stay near the top
- Still unfair : long running jobs may never get CPU
- countermeasure : put in meaningless I/O to keep job priority high. Cheat!
Figure:
The Mid-Week draw
- Handling fairness problems with above - would it hurt average response time ?
- Each queue is given a fraction of the CPU - what if 100 short running jobs but one long one
- Could adjust priorities : increase priority of jobs, as they don't get service -
as in Unix
- Ad hoc! - as system load goes up - no job gets CPU - so everyone increases priority.
Interactive jobs suffer
- Answer : Lottery Scheduling : every job has a number of lottery tickets,
and randomly picks a winning ticket at each time slice. On average, CPU time is proportional
to number of tickets given to each job
- Tickets are assigned as SRTCF : long ones get few - short ones get many. To avoid
starvation : every job gets at least one - hence everyone can make progress
- Major advantage : graceful behaviour with changing loads. Adding or deleting a job
affects everyone else proportionately - but independent of how many tickets each job gets
Scheduling on Unix
- Assigns base priorities (a high of -20 to a low of +20, with a median of 0)
- Priorities are adjusted according to changing system conditions
- Current priorities are calculated by adding to base values - process
with highest priority is dispatched first
- Priority adjustment is biased in favour of processes that have
recently used relatively little CPU
Scheduling on VAX/VMS
- VAX/VMS : process priorities range from 0-31, with 31 assigned to critical
real-time processes. Normal processes priorities range from 0-15, and real time
from 16 to 31
- Constant priorities for real-time processes (run to completion or preemption by
higher priority process)
- Normal process priorities do vary - their base priorities remain fixed,
but dynamic priority adjustment to give preference to I/O-bound processes over CPU-bound
processes
- Normal process retains the CPU until preempted, quantum expiry or a special state
event wait, with priority adjustment from 0 to 6 over their base level
- Processes with the same current priorities - scheduled as round robin
Next: About this document
Up: No Title
Previous: Scheduling - A Nightmare!!!
Omer F Rana
Tue Feb 11 19:18:07 GMT 1997