Structural concept learning systems are not without their problems.
The biggest problem is that the teacher must guide the system through carefully chosen sequences of examples.
In Winston's program the order of the process is important since new links are added as and when now knowledge is gathered.
The concept of version spaces aims is insensitive to order of the example presented.
To do this instead of evolving a single concept description a set of possible descriptions are maintained. As new examples are presented the set evolves as a process of new instances and near misses.
We will assume that each slot in a version space description is made up of a set of predicates that do not negate other predicates in the set -- positive literals.
Indeed we can represent a description as a frame bases representation with several slots or indeed use a more general representation. For the sake of simplifying the discussion we will keep to simple representations.
If we keep to the above definition the Mitchell's candidate elimination algorithm is the best known algorithm.
Let us look at an example where we are presented with a number of playing cards and we need to learn if the card is odd and black.
We already know things like red, black, spade, club, even card, odd card etc.
So the ![]() is red card, an even card and a heart.
is red card, an even card and a heart.
This illustrates on of the keys to the version space method specificity:
The training set consist of a collection of cards and for each we are told whether or not it is in the target set -- odd black
The training set is dealt with incrementally and a list of most and least specific concepts consistent with training instances are maintained.
Let us see how can learn from a sample input set:
The Candidate Elimination Algorithm
Let us now formally describe the algorithm.
Let G be the set of most general concepts. Let S be the set of most specific concepts.
Assume: We have a common representation language and we a given a set of negative and positive training examples.
Aim: A concept description that is consistent with all the positive and none of the negative examples.
Algorithm:
Let us now look at the problem of learning the concept of a flush in poker where all five cards are of the same suit.
Let the first example be positive:
![]()
Then we set
![]()
No the second example is negative:
![]()
We must specialise G (only to current set):
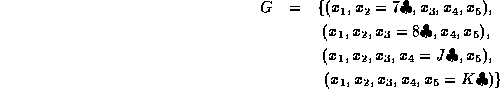
S is unaffected.
Our third example is positive:
![]()
Firstly remove inconsistencies from G and then generalise S:
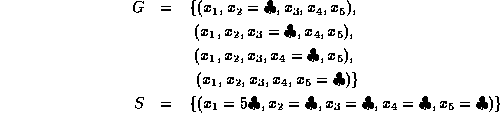
Our fourth example is also positive:
![]()
Once more remove inconsistencies from G and then generalise S:
![]()